On the impact of full-page writes
Tuning postgresql.conf, You may have noticed that there is a parameter full_page_writes. Existing side by side with him review says something about a partial record of pages and people usually leave it as on — that's not bad, I'll explain later in this article. However, it is very useful to understand that full_page_writes does, because the impact on the operation of the system may be significant.
Unlike my last post about the setting up of checkpoints, this is not a guide on how to configure the server. Here is not so much the fact that You could customize, actually, but I'll show You how some of the decisions at the application level (for example, the choice of data types) can interact with the writing of a complete page.
So what is a full record of the pages? Says review from postgresql.conf, it is a way to recover from a partial write pages, PostgreSQL uses a page size of 8kB (the default), while other parts of the stack use different sizes of pieces. Linux file system typically uses 4kB pages (use the page smaller, but 4kB is the maximum on x86), on a hardware level, the old drives use 512B sectors, while new write data is larger chunks (typically 4kB, 8kB or even).
Thus, when PostgreSQL writes 8kB page, the other layers of the repository can break it down into smaller pieces that are processed separately. This is a problem of atomicity of the record. The 8-Kbyte PostgreSQL'bcra page can be split into two 4kB pages in the file system, and then again on 512B sectors. Now, what happens if the server goes down (power failure, kernel bug,...)?
Even if the server uses a storage system designed to cope with such failures (SSD with capacitors, RAID controllers with batteries, ...), the kernel already splits the data into 4kB pages. There is a possibility that the database recorded a 8kB data page, but only part of it got to disk before the failure.
From this point of view, You are now probably thinking that this is something for which we have transactional log (WAL) and You're right! So, after starting the server, database read WAL (from the last completed checkpoint), and apply the changes again to make sure data files are correct. Simple.
But there's a trick — the recovery doesn't apply the changes blindly, often it is necessary to read data pages, etc., which implies that the page is not corrupted in some way, for example in connection with a partial record. That seems a little contradictory, because to fix data corruption, we mean that the data has not been corrupted.
Full record pages is something like solving this puzzle — when you change page the first time after a checkpoint, the whole page will be written to WAL. This ensures that during recovery, the first entry in WAL'e, associated with this page keeps a full page, freeing us from having to read potentially corrupted page from the data file.
Of course, the negative consequence is the increase in size WAL'and change one byte to 8kB page will lead to its full entry in WAL. The full record page occurs only on the first write after a checkpoint, that is, reducing the frequency of checkpoints is one way to improve the situation, in fact, there is a small "explosion" full of page writes after checkpoint, after which relatively few full recordings going on before it ends.
Still some unexpected interaction with design decisions at the application level. Let's assume we have a simple table with a primary key, UUID or BIGSERIAL, and we write data to it. Will there be any difference in the size of the generated WAL'and (assuming that we write the same number of rows)?
It seems reasonable to expect approximately the same size WAL's in both cases, but the following charts clearly demonstrate that there is a huge difference in practice:
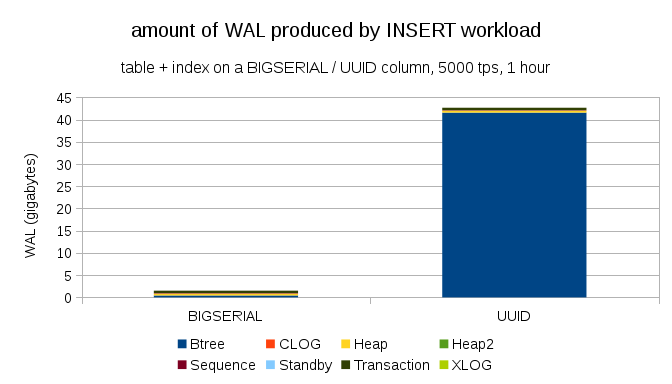
Here shows the sizes WAL's, the resulting time of the test, accelerate to 5000 inserts per second. BIGSERIAL'with om as a primary key, this resulted in a ~2GB WAL'Ayu while a UUID has issued more than 40GB. The difference is more than noticeable, and most of WAL'and is associated with an index standing for the primary key. Let's look at the types of records in WAL'e:

Obviously, the vast majority of the records are full — page images (FPI), i.e. the result of full record pages. But why is this happening?
Of course, this is due to the inherent UUID'have an accident. New BIGSERIAL's consistent, and written in the same branches of the btree index. So as soon as the first change the page causes a full page recording, a small number of records WAL'and are FPI'mi. With UUID it is quite another matter, of course, the values absolutely are not consistent and each insert is likely to be in the new branch of the index (assuming the index is quite large).
Database especially can't do anything with it — the load is random, which causes a large number of full page writes.
Of course, not so difficult to achieve a similar increase in recording even a BIGSERIAL keys. It just requires a different type of load, for example updates, random updates of records will change the distribution, the graph looks like the following:
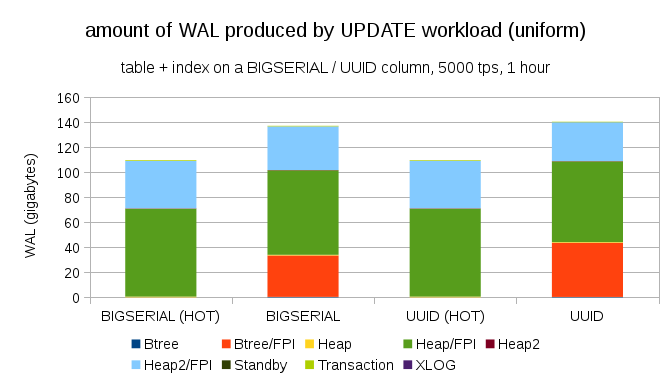
Suddenly the difference between data types disappeared — the access is done randomly in both cases, resulting in approximately the identical size produced WAL's. Another difference is the fact that most of WAL'and associated with the "heap", i.e. tables, not indexes. "HOT" cases were reproduced for the ability HOT UPDATE optimization (i.e. updates without having to touch code), which virtually eliminates all associated with indices WAL traffic.
But You may protest that most of the applications does not change the entire data set. Usually, only a small part of these "active" people interested in the posts in the last few days on the forums, the pending orders in online stores, etc. How does this affect results?
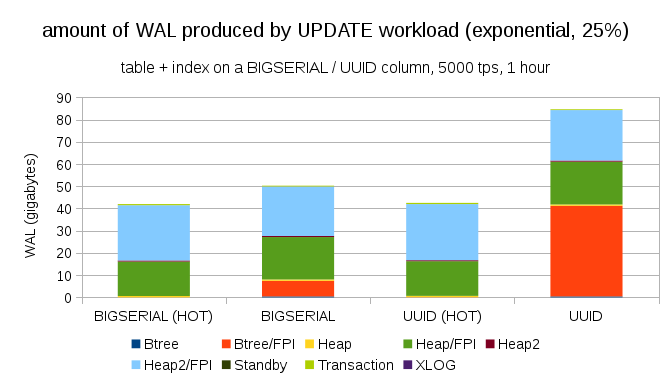
Fortunately, pgbench supports uneven distribution, and, for example, with the exponential distribution relating to 1% of the data set ~25% of the time, the charts will look like the following:
If you make a distribution more asymmetric, concerning 1% of the data ~75% of the time:
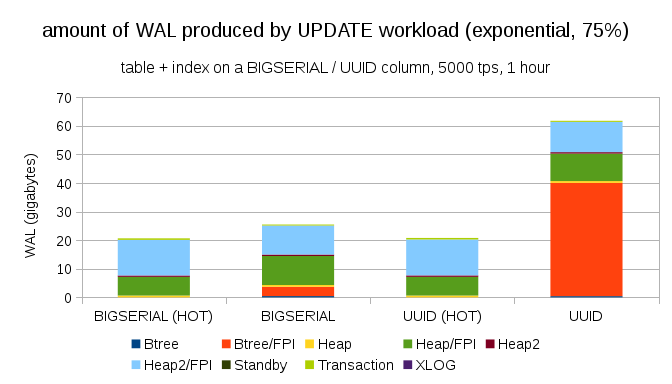
This once again shows how big a difference can cause a variety of types of data and how important is the setting of hot updates.
Another interesting question — how much WAL traffic, you can save money by using smaller pages in PostgreSQL (which requires compilation of a custom package). In the best case, this can save up to 50% WAL'and, thanks to the logging of only 4kB instead of 8kB pages. To load with evenly distributed with an update as follows:
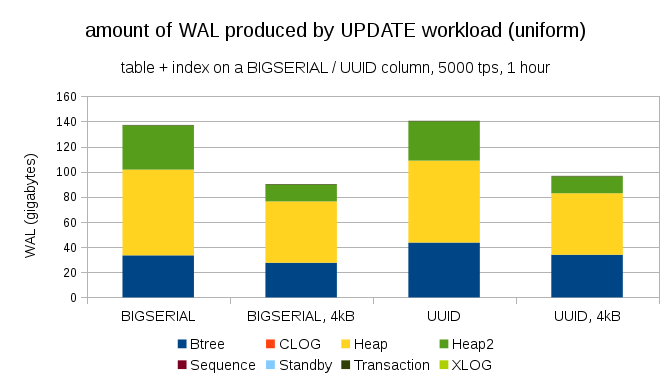
In General the savings are not quite 50%, but the decrease with ~140GB to ~90GB it's still quite noticeable.
It may seem glaring after explaining all the dangers of partial records, but may have off of the complete record pages can be a viable option, at least in some cases.
I spent a lot of tests recently trying to get a partial recording, but it couldn't have caused even a single case. Of course, this is not proof that the problem does not exist. But even if it is, the checksum may be sufficient protection (this does not fix the problem, but at least will point to the bad page).
Second, many modern systems rely on the replica that use streaming replication — instead of having to wait until the server restarts after a hardware failure (which can last quite a long time) and then spend even more time for recovery, the system just switches to the hot standby. If the database is corrupted on the master was removed (and then cloned with new master), partial records are not a problem.
But I'm afraid if we start to recommend this approach, then "I don't know how the data was corrupted, I just did full_page_writes=off on the system!" will be one of the most common suggestions just before the death of the DBA (along with "I saw this snake on reddit, she's not poisonous").
Not much can be done to directly configure a full record pages. For a larger number of loads, a large part of the full record occurs directly after a checkpoint, and then disappear until the next checkpoint. So it's pretty important to set checkpoints so that they do not follow each other too often.
Some of the decisions at the application level may increase the accident records in tables and indexes — for example UUID's by their nature random, turning even ordinary load of inserts in random updates of the indexes. The scheme used in the examples were quite trivial — in practice, there would be secondary indexes, foreign keys, etc. the Use BIGSERIAL as primary keys (and leaving the UUID as a side keys) can at least reduce the increase.
I'm really interested in the discussion of the need for a full record pages on different kernels/filesystems. Unfortunately, I have not found many resources if you have any relevant information, let me know.
Article based on information from habrahabr.ru
Unlike my last post about the setting up of checkpoints, this is not a guide on how to configure the server. Here is not so much the fact that You could customize, actually, but I'll show You how some of the decisions at the application level (for example, the choice of data types) can interact with the writing of a complete page.
Partial record / "Torn" pages
So what is a full record of the pages? Says review from postgresql.conf, it is a way to recover from a partial write pages, PostgreSQL uses a page size of 8kB (the default), while other parts of the stack use different sizes of pieces. Linux file system typically uses 4kB pages (use the page smaller, but 4kB is the maximum on x86), on a hardware level, the old drives use 512B sectors, while new write data is larger chunks (typically 4kB, 8kB or even).
Thus, when PostgreSQL writes 8kB page, the other layers of the repository can break it down into smaller pieces that are processed separately. This is a problem of atomicity of the record. The 8-Kbyte PostgreSQL'bcra page can be split into two 4kB pages in the file system, and then again on 512B sectors. Now, what happens if the server goes down (power failure, kernel bug,...)?
Even if the server uses a storage system designed to cope with such failures (SSD with capacitors, RAID controllers with batteries, ...), the kernel already splits the data into 4kB pages. There is a possibility that the database recorded a 8kB data page, but only part of it got to disk before the failure.
From this point of view, You are now probably thinking that this is something for which we have transactional log (WAL) and You're right! So, after starting the server, database read WAL (from the last completed checkpoint), and apply the changes again to make sure data files are correct. Simple.
But there's a trick — the recovery doesn't apply the changes blindly, often it is necessary to read data pages, etc., which implies that the page is not corrupted in some way, for example in connection with a partial record. That seems a little contradictory, because to fix data corruption, we mean that the data has not been corrupted.
Full record pages is something like solving this puzzle — when you change page the first time after a checkpoint, the whole page will be written to WAL. This ensures that during recovery, the first entry in WAL'e, associated with this page keeps a full page, freeing us from having to read potentially corrupted page from the data file.
Increase
Of course, the negative consequence is the increase in size WAL'and change one byte to 8kB page will lead to its full entry in WAL. The full record page occurs only on the first write after a checkpoint, that is, reducing the frequency of checkpoints is one way to improve the situation, in fact, there is a small "explosion" full of page writes after checkpoint, after which relatively few full recordings going on before it ends.
UUID vs BIGSERIAL keys
Still some unexpected interaction with design decisions at the application level. Let's assume we have a simple table with a primary key, UUID or BIGSERIAL, and we write data to it. Will there be any difference in the size of the generated WAL'and (assuming that we write the same number of rows)?
It seems reasonable to expect approximately the same size WAL's in both cases, but the following charts clearly demonstrate that there is a huge difference in practice:
Here shows the sizes WAL's, the resulting time of the test, accelerate to 5000 inserts per second. BIGSERIAL'with om as a primary key, this resulted in a ~2GB WAL'Ayu while a UUID has issued more than 40GB. The difference is more than noticeable, and most of WAL'and is associated with an index standing for the primary key. Let's look at the types of records in WAL'e:
Obviously, the vast majority of the records are full — page images (FPI), i.e. the result of full record pages. But why is this happening?
Of course, this is due to the inherent UUID'have an accident. New BIGSERIAL's consistent, and written in the same branches of the btree index. So as soon as the first change the page causes a full page recording, a small number of records WAL'and are FPI'mi. With UUID it is quite another matter, of course, the values absolutely are not consistent and each insert is likely to be in the new branch of the index (assuming the index is quite large).
Database especially can't do anything with it — the load is random, which causes a large number of full page writes.
Of course, not so difficult to achieve a similar increase in recording even a BIGSERIAL keys. It just requires a different type of load, for example updates, random updates of records will change the distribution, the graph looks like the following:
Suddenly the difference between data types disappeared — the access is done randomly in both cases, resulting in approximately the identical size produced WAL's. Another difference is the fact that most of WAL'and associated with the "heap", i.e. tables, not indexes. "HOT" cases were reproduced for the ability HOT UPDATE optimization (i.e. updates without having to touch code), which virtually eliminates all associated with indices WAL traffic.
But You may protest that most of the applications does not change the entire data set. Usually, only a small part of these "active" people interested in the posts in the last few days on the forums, the pending orders in online stores, etc. How does this affect results?
Fortunately, pgbench supports uneven distribution, and, for example, with the exponential distribution relating to 1% of the data set ~25% of the time, the charts will look like the following:
If you make a distribution more asymmetric, concerning 1% of the data ~75% of the time:
This once again shows how big a difference can cause a variety of types of data and how important is the setting of hot updates.
8kB and 4kB page
Another interesting question — how much WAL traffic, you can save money by using smaller pages in PostgreSQL (which requires compilation of a custom package). In the best case, this can save up to 50% WAL'and, thanks to the logging of only 4kB instead of 8kB pages. To load with evenly distributed with an update as follows:
In General the savings are not quite 50%, but the decrease with ~140GB to ~90GB it's still quite noticeable.
do we Need full record of the pages?
It may seem glaring after explaining all the dangers of partial records, but may have off of the complete record pages can be a viable option, at least in some cases.
I spent a lot of tests recently trying to get a partial recording, but it couldn't have caused even a single case. Of course, this is not proof that the problem does not exist. But even if it is, the checksum may be sufficient protection (this does not fix the problem, but at least will point to the bad page).
Second, many modern systems rely on the replica that use streaming replication — instead of having to wait until the server restarts after a hardware failure (which can last quite a long time) and then spend even more time for recovery, the system just switches to the hot standby. If the database is corrupted on the master was removed (and then cloned with new master), partial records are not a problem.
But I'm afraid if we start to recommend this approach, then "I don't know how the data was corrupted, I just did full_page_writes=off on the system!" will be one of the most common suggestions just before the death of the DBA (along with "I saw this snake on reddit, she's not poisonous").
Output
Not much can be done to directly configure a full record pages. For a larger number of loads, a large part of the full record occurs directly after a checkpoint, and then disappear until the next checkpoint. So it's pretty important to set checkpoints so that they do not follow each other too often.
Some of the decisions at the application level may increase the accident records in tables and indexes — for example UUID's by their nature random, turning even ordinary load of inserts in random updates of the indexes. The scheme used in the examples were quite trivial — in practice, there would be secondary indexes, foreign keys, etc. the Use BIGSERIAL as primary keys (and leaving the UUID as a side keys) can at least reduce the increase.
I'm really interested in the discussion of the need for a full record pages on different kernels/filesystems. Unfortunately, I have not found many resources if you have any relevant information, let me know.



Комментарии
Отправить комментарий